Paul’s Journal
Some things of interest to Paul Hammond, arranged in a reverse chronological order with a feed
25 May 2021
Sometimes while I’m working on a project I have a sudden realization that two
components aren’t connected the way everyone thinks they are. Often this is just
a bug, usually one the team has been chasing for a while. Occasionally it’s a
security hole. But I rarely get to write about it because the components are
deep inside the infrastructure of a company that pays my wages.
Recently I had this experience while working with Visual Studio Code Remote
Containers which resulted in my first public CVE
number, so I’m going to take a moment to write about it, remind
you that it’s easy to escape a Docker container, and that developer laptops are
probably the weakest link in any company’s security.
VS Code has an action called “Remote-Containers: Clone Repository in Container
Volume” which automates the process of downloading a codebase, installing all of
the dependencies in a Docker container, running that container, and attaching
your editor. I found a small problem: it’s possible for code in the the
repository to escape the sandbox provided by Docker and get root privileges on
the host system.
To do this you need to do two things:
- You need to run arbitrary code inside the container. Usually VSCode ignores the
Docker entrypoint and always runs its own shell scripts, but there are many
ways to get it to do something else. For example you can replace
/bin/sh with a
shell script that runs whatever you want, or just provide a postCreate or
postAttach command.
- You need to escape the container. The
devcontainer.json file inside the
repository can specify arguments to the docker run command, which gives it the
ability to mount almost any directory in the container. Notably you can mount
the Docker socket file, and once you have access to that you can get root
privileges on the host system.
Combine these and someone just clicking on UI elements inside VSCode can find
their laptop compromised. After I reported the issue Microsoft added a simple
warning before you perform the action, which is about as good a fix as they can
do given there are so many possible variations on both halves of this attack.
Even though I’m writing about it and I reported it to Microsoft
Security, I don’t think this is a serious bug. Programmers have been
downloading untrusted code and running it locally since before I was born and
there are much easier ways to convince them to do this than a little known
feature of a VS Code extension. curl | sudo bash or ./configure && make && sudo make install are the two obvious variations, but any time you run
something like npm install followed by npm start you’re hoping that none of
the repositories you just downloaded contain anything malicious.
I also think the style of containerized development environment that Microsoft
are building is likely to eventually be more secure than directories on laptops,
even if there are problems along the way. Variations on this attack will have to
be more advanced to work on a hosted product such as Github
Codespaces. The costs of a sandbox escape there are a lot higher,
so the development team does more work to avoid them and it’s more likely that
centralized intrusion detection will catch an attack in action. And, even if
someone did manage to escape, the impact is lower; they'll only have access to a
few other projects that happen to be running on the same server, and not access
to all of your keys, tokens and every photo you’ve taken in the last few years.
My experience is that developers demand the ability to run anything they want on
their computers, even at companies with tightly locked down device management
policies. I’m also only aware of maybe a dozen companies where long-lived
production credentials never ever touch developer laptops. Given the apparent
rise of software supply chain attacks recently, I wonder if both of those should
change. Or maybe we’ll keep stumbling along hoping for the best.
■
23 October 2020
I’ve switched all of my development over to
VS Code Remote Containers and it’s working really well.
Having every project isolated with its own runtime means I don’t have to upgrade
every project at the same time, and I no longer find that half my projects have
broken thanks to a macOS or homebrew upgrade.
The one challenge is that Node.js projects can be much slower when running in a
container. This is not surprising, since these projects usually have tens of
thousands of files inside the node_modules directory. That directory is inside
a Docker bind mount and Hyperkit needs to do a lot of extra
work to keep all those files in sync with the host computer.
The VS Code documentation discusses this problem and suggest
using a named volume to improve disk performance, but
doing this requires managing Docker volumes outside of VS Code, and in my
subjective experience didn’t seem to result in much improvement in speed.
Instead, I’ve started using RAM disks, which are faster and can be managed
entirely within the devcontainer.json file:
{
"name": "node",
"build": { "dockerfile": "Dockerfile" },
"runArgs": [
"--tmpfs",
"${containerWorkspaceFolder}/node_modules:exec"
],
"postStartCommand":
"sudo chown node node_modules && npm i",
…
}
The runargs config adds an argument to the docker run command. This
particular argument tells Docker to create a new tmpfs at
/workspaces/project/node_modules . The exec flag is needed by a handful of
packages that install helper scripts, otherwise Linux will ignore the executable
bit on those files.
The postStartCommand then ensures that every time the container is started we
give the node user write access to this directory. We also run npm i for
good measure.
The end result is a container where node_modules is stored in RAM, and Docker
knows that it’s not important data so doesn’t do extra work to sync it to disk.
As a result everything is faster.
■
6 February 2020
I just released version 0.3 of jp. It fixes the tiniest of tiny bugs
where in very obscure cases it might turn your shell prompt green. Also a new
release comes with new pre-made binaries, which have been compiled with a more
recent version of Go, which means they run on newer versions of macOS.
But, honestly, none of that was the point of the new release. Since leaving
Slack a while back (more on that later, maybe) I’ve been spending time exploring
all the technology changes that happened while I was busy with a hypergrowth
startup. One of the interesting ones is Github
Actions. You can use Actions to run any
code in a short-lived container whenever something happens in a Github repo.
This opens up so many possibilities. But to really learn a technology you have
to actually use it, and jp just happens to be where I’m trying this one out.
In this case I’m using Actions and Go’s cross compilation support to
automatically build binaries for Mac and Linux on every push. When I tag a new
release page a new draft GitHub release page is made, and binary downloads are
added to it. It’s all pretty basic, but it means that the entire build process
is now reproducible, instead of relying on the state of the Homebrew install on
my laptop.
This feels related to a lot of work happening on VS
Code, like Recommended
Extensions,
Workspace Settings,
and Remote
Development. Every
aspect of a project can now easily be checked into version control. This was
always possible, and necessary, for huge projects with many engineers, but it
felt like too much work for tiny projects. Now it’s just a handful of YAML and
JSON files.
So hopefully the next time I dust off a seven year old project on a new laptop
it’ll take less than a few hours to get it working again.
■
19 May 2014
It’s been over a year since the last release of webkit2png, it’s about time for a
new one.
This is mostly a bugfix release. The new version does a much better job of handling both retina displays and local files, thanks to Ben Alpert,
Sean Coates, and Jeremy Stucki
There are also a handful of new features:
You can see the full list of changes or download the code.
■
12 March 2014
Today is my first day at Tiny Speck, purveyors of the awesome Slack.
A few weeks back I realized that almost all of the ideas I’ve been working on were incredibly similar to the tools that my friends over there were building. It turns out that most of the problems in operations these days are communication and coordination problems, that the challenge is not getting more data but finding ways to talk about the data you already have. The Slack team have been working on this problem for longer than I have and their approach seems to be working. They’re also really nice people, so when I got the opportunity to work with them the decision was obvious.
Initially I’ll be working on making Slack integrations easier. They’re already ridiculously easy but there is still more to do. I’ll be writing better documentation, adding new APIs, making the existing APIs better and doing whatever else is needed to help you write code that talks to people. If you have ideas, let me know.
After that, who knows? Whatever happens it’s going to be fun.
■
8 March 2014
Version 0.2 of jp is out. It fixes a small bug where significant whitespace was
removed from invalid JSON documents. More importantly it also adds some color to
the output:
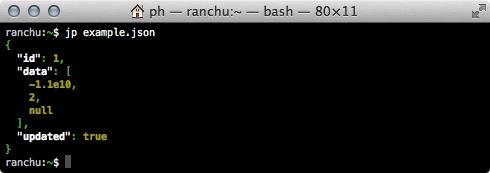
Color didn’t make it into the first version of jp, but it was one of the
reasons I built a new parser when I started writing the code. Adding
ANSI Escape codes to one of
the many existing general-purpose JSON libraries would be possible, but I’m
not convinced it would be the right thing to do. Most JSON code is now
part of the core library for any language and adding extra code to every JSON
generating application to handle this one specific use case is a waste of CPU
and future developer debugging time. Even if a patch were appropriate, it
would take a really long time before I could rely on the functionality being
on a system, so I wrote a new library for this use case.
In general it’s hard to argue against code reuse as a concept; none of the
computers systems we use today would be possible without it. But sometimes we
take that concept too far, and try to reuse code in a context it wasn’t
designed for, or write code to handle every use case when just one is needed.
Greg Wilson’s
“What We Actually Know About Software Development”
is, in my view, one of the best presentations ever given about code. If you
haven’t watched it, you should. Around 32 minutes in he talks about some
research from Boeing that suggests “if you have to rewrite more than about a
quarter of a software component, you’re actually better off rewriting it from
scratch”. This seems like a small but useful example of that effect in action.
But I digress. If you want your JSON in color
you should get the latest jp.
■
19 January 2014
Logtime is a small service that makes timestamps human readable.
Anyone who’s spent any time debugging production systems has had the frustrating experience of trying to correlate the timestamps in a log file with something that happened in the real world.
The log files are usually in UTC when you want them in localtime, or worse, the other way around. Even if you can remember that San Francisco is 8 hours ahead of UTC in the winter actually doing the mental arithmetic is annoying. And some log files helpfully use unreadable timestamps like @4000000052d7c9e300000000 or 1389873600. If you’re lucky you can remember the right incantations to the date command to convert what you want; I can’t so I made something instead.
It’s not quite done. I’m sure I’ve missed a few common time formats, and I’d like to see how, and if, it gets used before working out what to add next.
■
21 November 2013
s3simple is a small Bash script to fetch files from and upload files to Amazon’s S3 service.
It was written to help with a fairly common case: you want to download some data from a protected S3 bucket but you don’t have a full featured configuration management system to help you install the software to do so. Perhaps the data is part of your server bootstrapping process, perhaps you just want to download and run an application tarball on a temporary server as quickly as possible, perhaps this is part of a build script that needs to run on developer laptops.
Usually in this scenario s3cmd is used. S3cmd is great; it’s powerful, feature complete, flexible and available in most distributions. But it’s not set up to use in an adhoc way. To run it with a set of one-off IAM keys you need to create a configuration file, then run s3cmd with extra command line options pointing to that configuration file, then clean up the configuration file when you’re done.
In comparison, s3simple takes an S3 url and uses the same two AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables as most AWS tools. It only has two dependencies (openssl and curl) which are installed or easily available on all modern unixes. And it’s a simple bash function that’s easy to integrate into a typical bootstrapping script.
I’ve found it useful. I hope you do too.
■
16 April 2013
Most JSON APIs return data in a format optimized for speed over human
readability. This is good, except when things are broken.
But that’s OK, because we have Unix Pipes and we can pipe the JSON into a prettifier. But all of the prettifiers start with a JSON parser so they don’t work if the data is invalid. Most of them also make small changes to the data as it passes through – strings get normalized, numbers get reformatted, and so on – which means you can’t be totally sure if your output is accurate. And they’re usually slow.
Last night I wrote a tool called jp which doesn’t have these problems. It works
by doing a single pass through the JSON data adding or removing whitespace as needed.
It’s fast. Absurdly fast. Reformatting a 161M file on my laptop takes 13 seconds, compared to 44 seconds for JSONPP, or several minutes for the Ruby or Python alternatives. And it’s accurate; it doesn’t change any of the data, just the spaces around it.
You should use it.
■
30 March 2013
I just released version 0.6 of webkit2png.
It’s been 4 years since the last release of webkit2png. That’s too long, particularly when you consider how many people have contributed fixes and features since the code moved to GitHub. In no particular order:
I’m amazed and grateful that every one of these people took their time to make webkit2png better. Thank you.
Oh, and there’s one more experimental feature that didn’t make the release. I’d love to hear if it works for anyone.
■